
FIELDCRAFT #004 — THE RAW DATA
The Press Release Is the Cover Story. The Preprint Is the Primary Source.


SUBJECT: SCIENTIFIC PREPRINT ANALYSIS AS PRIMARY INTELLIGENCE // ARXIV MONITORING, DATA TABLE FORENSICS, CROSS-PAPER TRIANGULATION, INSTITUTIONAL RESPONSE TRACKING
DATE: APRIL 11, 2026
CROSS-REF: FIELDCRAFT SERIES | THE ANCIENT ENGINE | THE VERDICT | THE WEIGH-IN | THE WIDE ANGLE
DATA CONFIDENCE: VERIFIED (all tools referenced are publicly accessible, all methods are reproducible)
This is the fourth installment of FIELDCRAFT. The briefings give you the intelligence. FIELDCRAFT gives you the tradecraft.
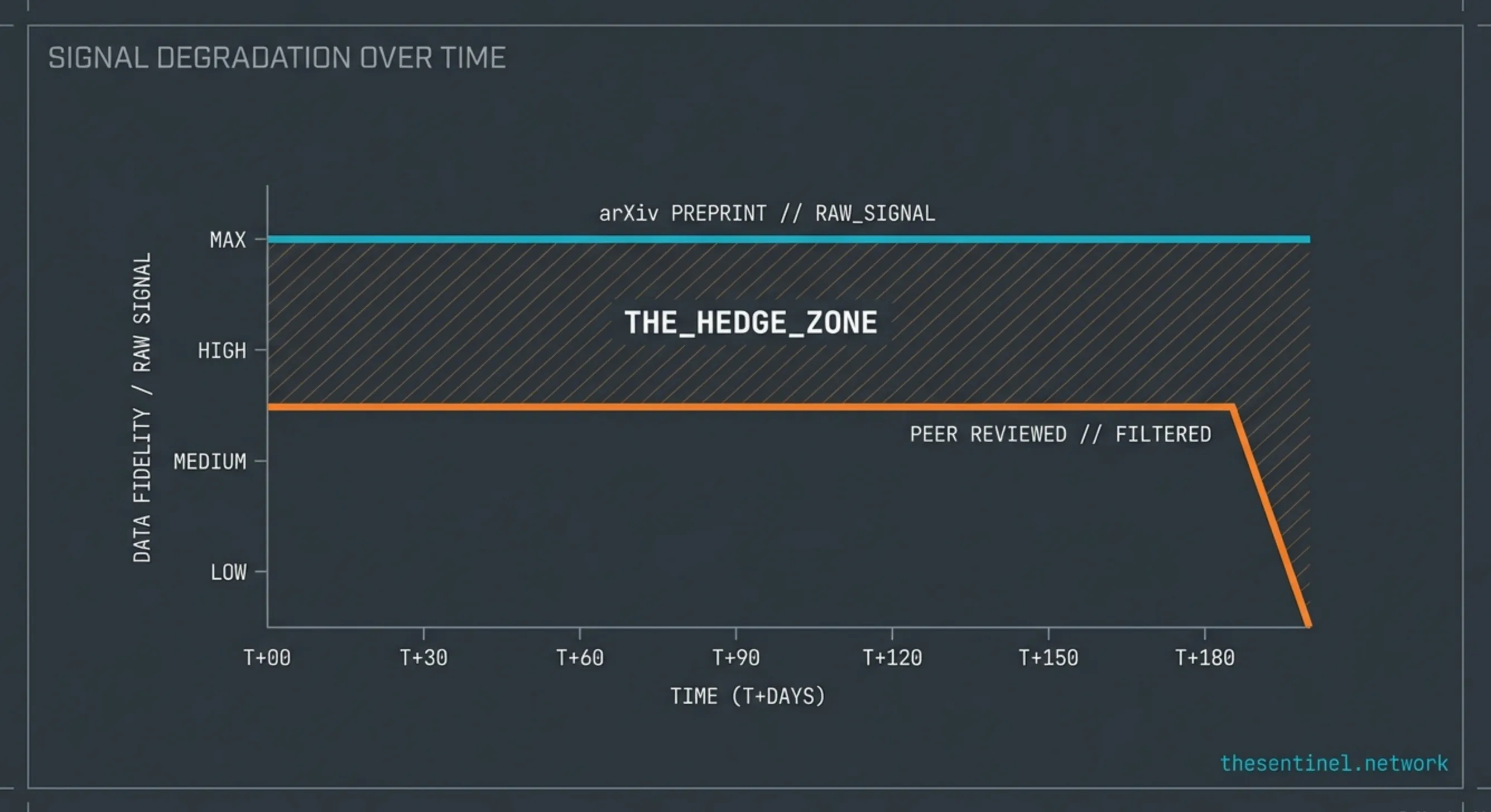
Why Preprints
A preprint is a scientific paper posted publicly before peer review. The author finishes the paper, uploads it to a server like arXiv, and it is readable within a day. No paywall. No editorial filter. No six-month journal embargo.
Separately, the author submits the same paper to a journal. The journal sends it to peer reviewers. That process takes weeks to months. If accepted, it gets published in the journal as peer-reviewed work. Sometimes with changes. Sometimes with significant changes.
The preprint is the unfiltered version. The data before the review process softens, hedges, or reshapes it. Every major finding in The Sentinel Network 3I/ATLAS catalog came from reading preprints the day they posted on arXiv.
This installment teaches you how to find them, how to set up passive collection so they come to you, how to read them even if you are not a scientist, and how to extract the findings that the authors themselves buried.
Step 1: Set Up Your Collection Pipeline
Do this first. Before you read a single paper. You want the papers coming to you automatically so you never miss a drop.